library(tidyverse)
library(tidymodels)
library(knitr)
library(patchwork)
# add other packages as neededLab 04: Exam 01 Review
ImportantDue date
This lab is due on Sunday, February 15 at 11:59pm. To be considered on time, the following must be done by the due date:
- Final
.qmdand.pdffiles pushed to your team’s GitHub repo - Final
.pdffile submitted on Gradescope
Getting Started
Go to the sta221-sp26 organization on GitHub. Click on the repo with the prefix lab-04. It contains the starter documents you need to complete the lab.
Clone the repo and start a new project in RStudio. See the Lab 00 instructions for details on cloning a repo and starting a new project in R.
Each person on the team should clone the repository and open a new project in RStudio. Throughout the lab, each person should get a chance to make commits and push to the repo
Packages
You will need the following packages for the lab:
Restaurant tips
What factors are associated with the amount customers tip at a restaurant? To answer this question, we will use data collected in 2011 by a student at St. Olaf who worked at a local restaurant.1
The variables we’ll focus on for this analysis are
Tip: amount of the tipParty: number of people in the partyAge: Age of the payer
View the data set to see the remaining variables.
tips <- read_csv("data/tip-data.csv")Exploratory data analysis
p1 <- ggplot(data = tips, aes(x = Tip)) +
geom_histogram(color = "white", binwidth = 2) +
labs(x = "Tips ($)",
title = "Tips at local restaurant")
p2 <- ggplot(data = tips, aes(x = Party)) +
geom_histogram(color = "white") +
labs(x = "Party",
title = "Number of diners in party") +
xlim(c(0, 7))
p3 <- ggplot(data = tips, aes(x = Age)) +
geom_bar(color = "white") +
labs(x = "",
title = "Age of Payer")
p1 / (p2 + p3)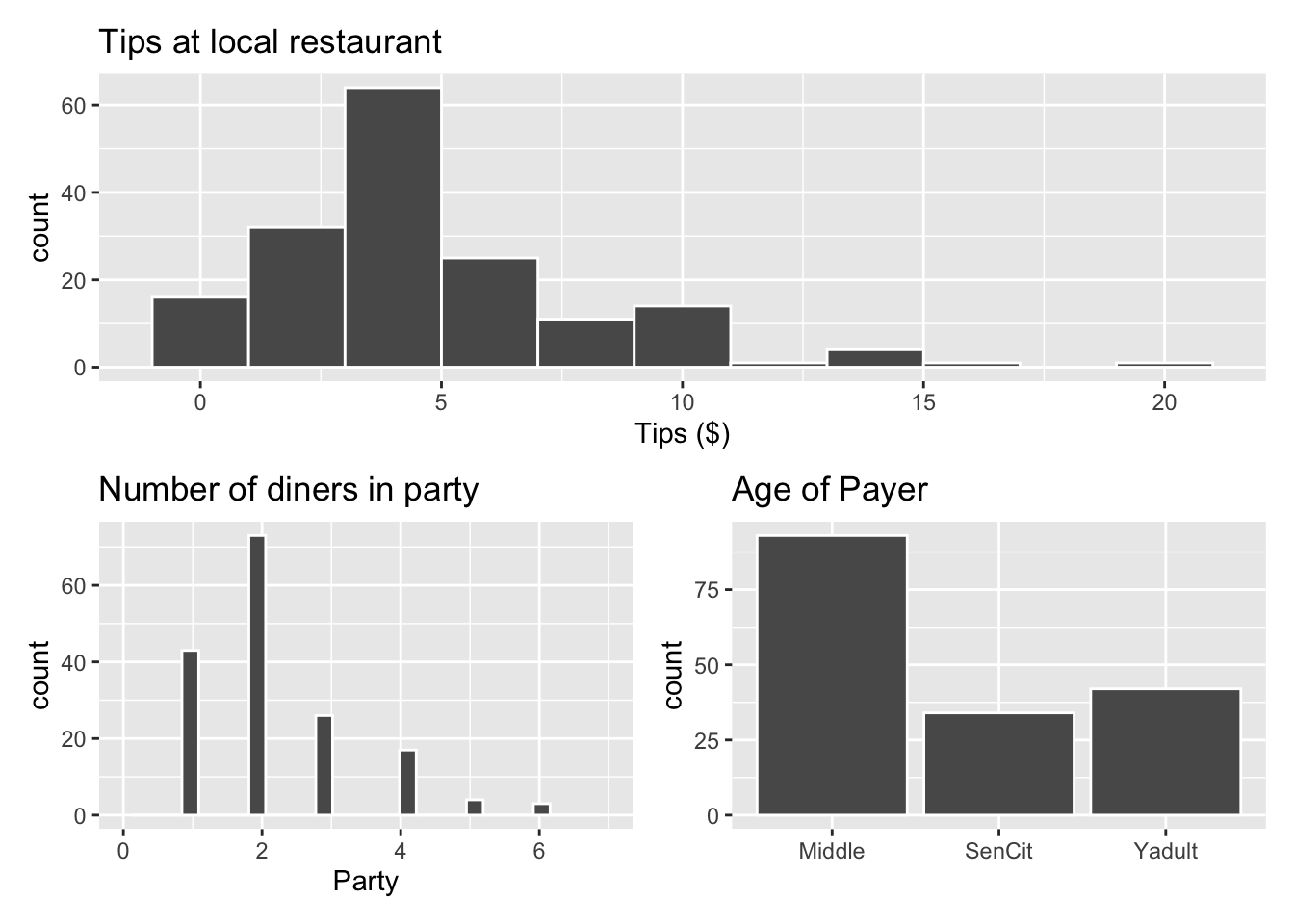
p4 <- ggplot(data = tips, aes(x = Party, y = Tip)) +
geom_jitter() +
labs(x = "Number of diners in party",
y = "Tips ($)",
title = "Tips vs. Party")
p5 <- ggplot(data = tips, aes(x = Age, y = Tip)) +
geom_boxplot() +
labs(x = "Age of payer",
y = "Tips ($)",
title = "Tips vs. Age")
p4 + p5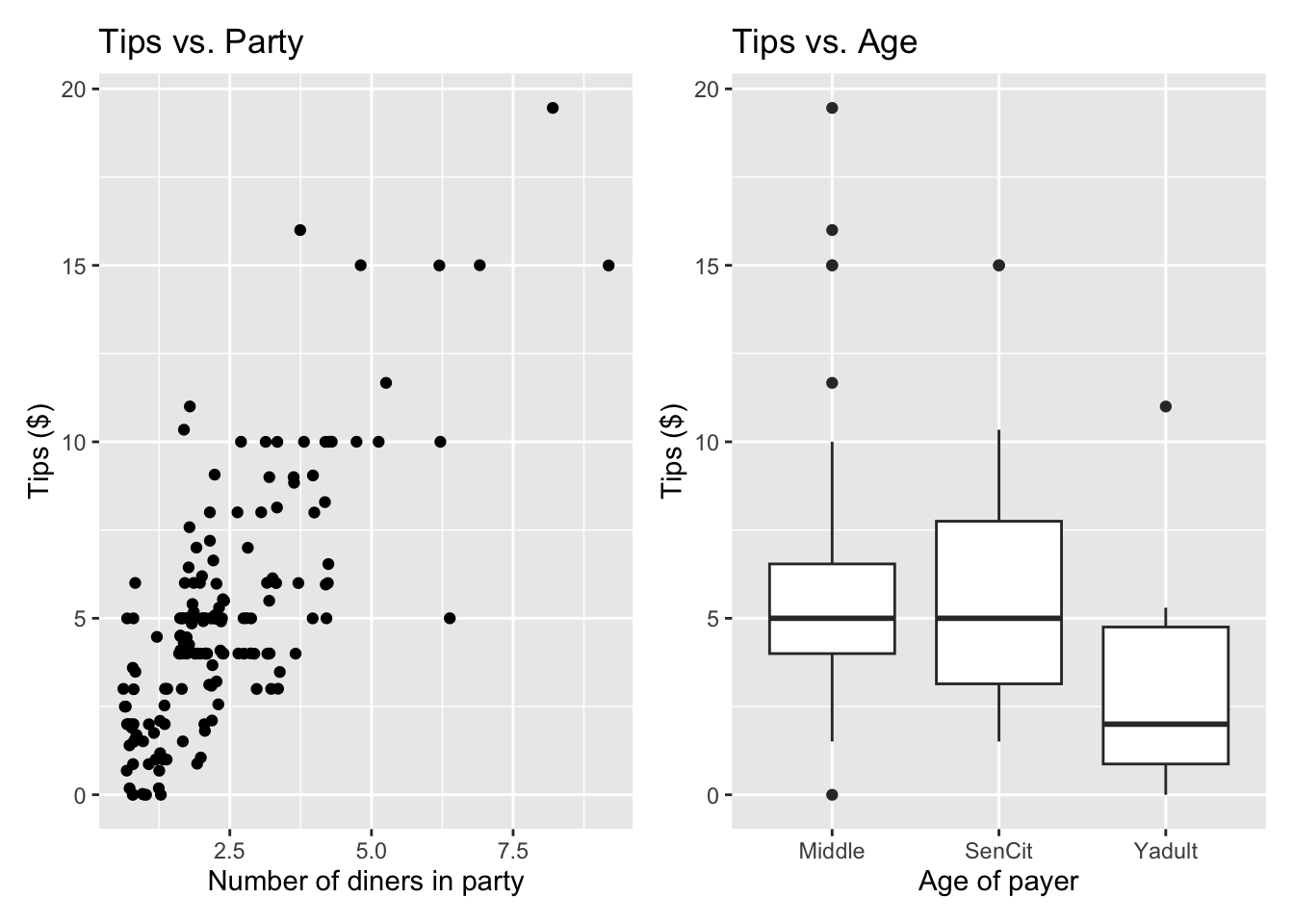
We will use the number of diners in the party and age of the payer to understand variability in the tips.
Exercise 1
We will start with the main effects model that includes Age and Party.
How many indicator variables for
Agecan we create from the data?How many indicator variables for
Agewill be in the regression model?Are the responses to parts a and b equal? If not, explain why not.
Which of the following is true for this model? Select all that apply.
- The intercepts are the same for every level of
Age. - The intercepts differ by
Age. - The effect of
Partyis the same for every level ofAge. - The effect of
Partydiffers byAge.
- The intercepts are the same for every level of
Exercise 2
Consider the main effects model that includes Age and Party.
What is the dimension of the design matrix \(\mathbf{X}\) for the main effects model?
Calculate the coefficient estimates \(\hat{\boldsymbol{\beta}}\) directly from the data.
Write the equation of the estimated regression model.
Exercise 3
Consider the main effects model that includes Age and Party. Get \(\mathbf{y}\) and \(\mathbf{X}\) from the data.
Use \(\mathbf{y}\) and \(\mathbf{X}\) to compute \(\hat{\sigma}_{\epsilon}\) .
Interpret \(\hat{\sigma}_\epsilon\) in the context of the data.
Compute \(Var(\hat{\boldsymbol{\beta}})\).
You wish to test whether there is a linear relationship between tips and the number of diners in the party, after adjusting for the age of the payer. Compute the test statistic. Explain what it means in the context of the data.
Use the code below to compute the p-value and explain what it means in the context of the data.
State the conclusion from the test in the context of the data.
2 * pt(abs(test-statistic), df, lower.tail = FALSE)Exercise 4
Consider the main effects model that includes Age and Party. Get \(\mathbf{y}\) and \(\mathbf{X}\) from the data.
Use \(\mathbf{y}\) and \(\mathbf{X}\) to compute \(R^2\). Interpret this value in the context of the data.
Use \(\mathbf{y}\) and \(\mathbf{X}\) to compute \(RMSE\). Interpret this value in the context of the data.
Exercise 5
You decide to add an interaction effect between Age and Party to the model and fit a model of the following form:
\[ \begin{aligned} Tip_i = \beta_0 &+ \beta_1Party_i + \beta_2SenCit_i + \beta_3Yadult_i \\ &+ \beta_4Party_i \times SenCit_i + \beta_5 Party_i \times Yadult_i \\ &+ \epsilon_i \end{aligned} \]
Which of the following is true for this model? Select all that apply.
The intercepts are the same for every level of
Age.The intercepts differ by
Age.The effect of
Partyis the same for every level ofAge.The effect of
Partydiffers byAge.
By how much does the intercept for tables with young adult payers differ from tables with middle age payers? Write the answer in terms of the \(\beta\)’s.
Write the equation of the model for tables in which the payer is a senior citizen.
Suppose you wish to test the hypotheses: \(H_0: \beta_5 = 0 \text{ vs. }H_a: \beta_5 \neq 0\) . State what is being tested in terms of the effect of
Party.
Exercise 6
Use the lm() function to fit the model that includes Age and Party and the interaction between the two variables. Display the 90% confidence interval for the coefficients.
The standard error for
AgeSenCitis 0.784. State what this value means in the context of the data.Write code to show how the 90% confidence interval for
AgeSenCitwas computed.Based on the confidence interval, is there evidence that tables with senior citizen payers tip differently on average than tables with middle age payers?
Submission
You will submit the PDF documents for labs, homework, and exams in to Gradescope as part of your final submission.
Warning
Before you wrap up the assignment, make sure all documents are updated on your GitHub repo. We will be checking these to make sure you have been practicing how to commit and push changes.
Remember – you must turn in a PDF file to the Gradescope page before the submission deadline for full credit.
To submit your assignment:
Access Gradescope through the menu on the STA 221 Canvas site.
Click on the assignment, and you’ll be prompted to submit it.
Select the name of every team member.
Mark the pages for the “Exercises” question.
Select the first page of your .PDF submission to be associated with the “Team agreement” and “Workflow & formatting” questions.
Grading (10 pts)
This lab will be graded based on completion and workflow & formatting. The point breakdown is as follows:
| Component | Points |
|---|---|
| Complete exercises | 8 |
| Workflow & formatting | 2 |
8 pts: Complete all exercises
7 pts: Complete 5 exercises
6 pts: Complete 4 exercises
5 pts: Complete 3 exercises
4 pts: Complete 2 exercises
0 pts: Complete < 2 exercises
Workflow & formatting
The “Workflow & formatting” grade is to assess the reproducible workflow and collaboration. This includes having at least one meaningful commit from each team member and updating the team name and date in the YAML.
2 pts: Meet all criteria
1 pt: Meet some criteria
0 pt: Meet no criteria
Footnotes
Dahlquist, Samantha, and Jin Dong. 2011. “The Effects of Credit Cards on Tipping.” Project for Statistics 212-Statistics for the Sciences, St. Olaf College.↩︎