Ridge regression
Mar 19, 2026
Finding the ridge estimator
The ridge optimization problem can also be written
\[\text{minimize }(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta}) \hspace{2mm} \text{subject to} \hspace{2mm} ||\boldsymbol{\beta}||^2_2 \leq c^2\] for some constant \(c\) . Note: \(||\boldsymbol{\beta}||_2 = \sqrt{\sum_{j=1}^p\beta_j^2}\)
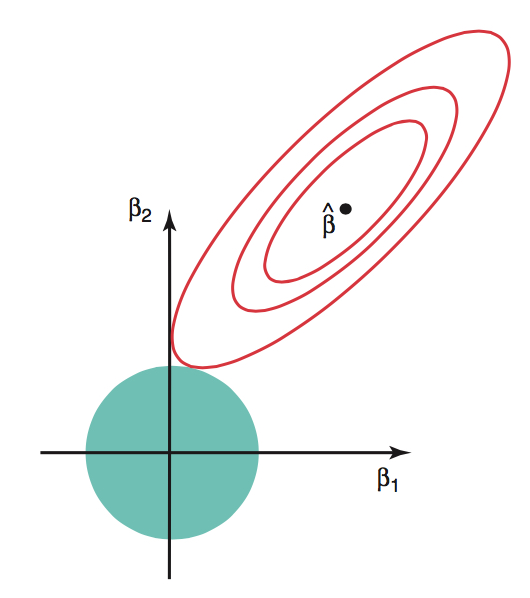
Red contours are combinations of \(\beta_1\) and \(\beta_2\) that result in same SSR
Blue circle is set of possible values of \(\beta_1\) and \(\beta_2\) given the constraint
Ridge solution at tangent
See Section 1.5 of Lecture notes on ridge regression for details.
Try different values of lambda
Code
lambdas <- seq(0, 1000, length = 5000)
ridge_fit <- MASS::lm.ridge(Age ~ Sex + Length + Diameter + Height + Whole_Weight,
data = abalones, lambda = lambdas)
# Plot ridge trace
plot(ridge_fit, main = "Ridge Trace Plot")
coef_names <- colnames(coef(ridge_fit))
coef_names <- coef_names[coef_names != "(Intercept)"]
n <- length(coef_names)
colors <- palette()[1:n]
legend(
x = "topright",
legend = coef_names,
col = colors,
lty = 1:n,
lwd = 2,
title = "Coefficients",
bty = "n",
cex = 0.8
)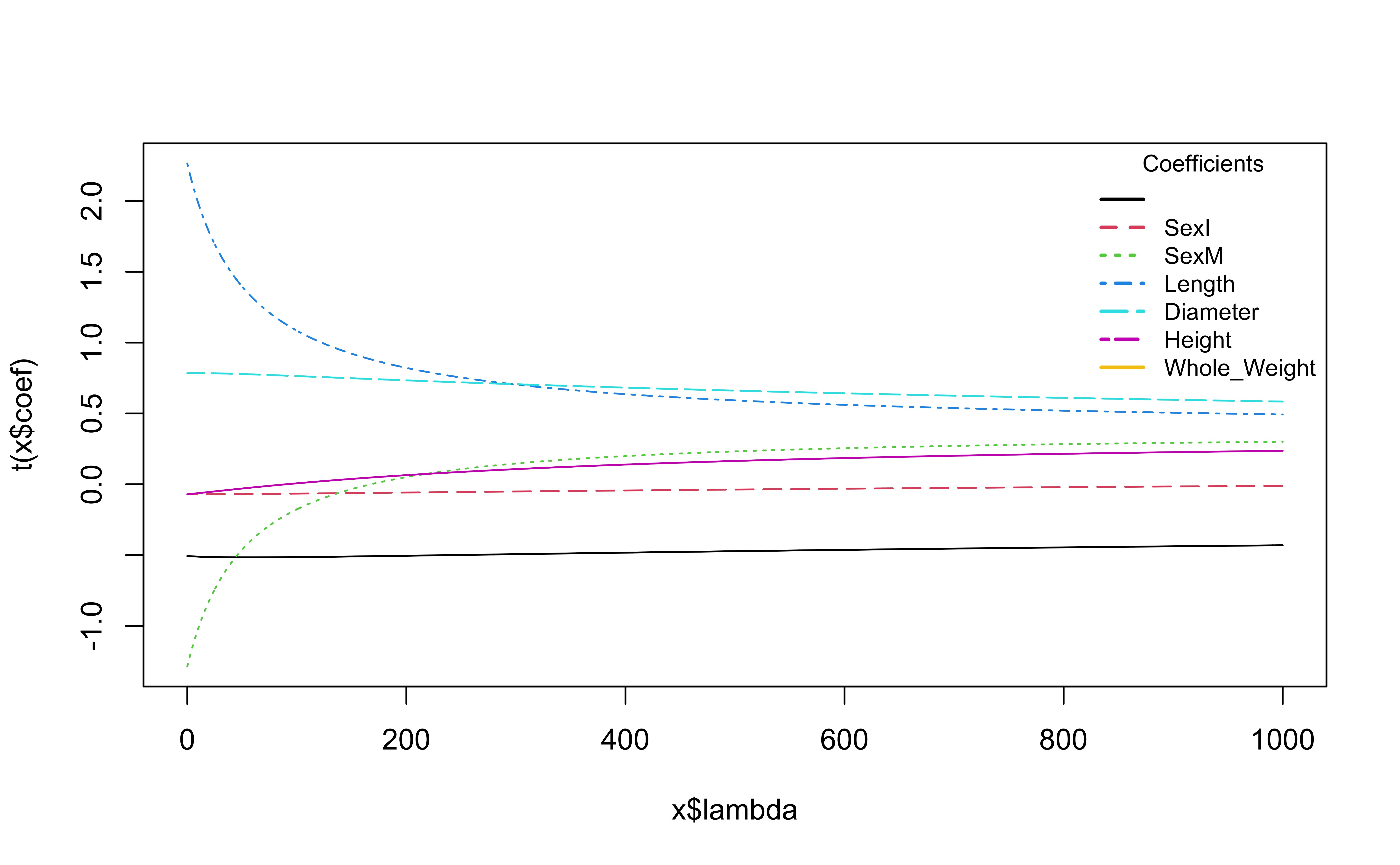
What is happening to the coefficients as \(\lambda\) increases?