Data science ethics
Apr 07, 2026
When things go wrong
Gap in public trust
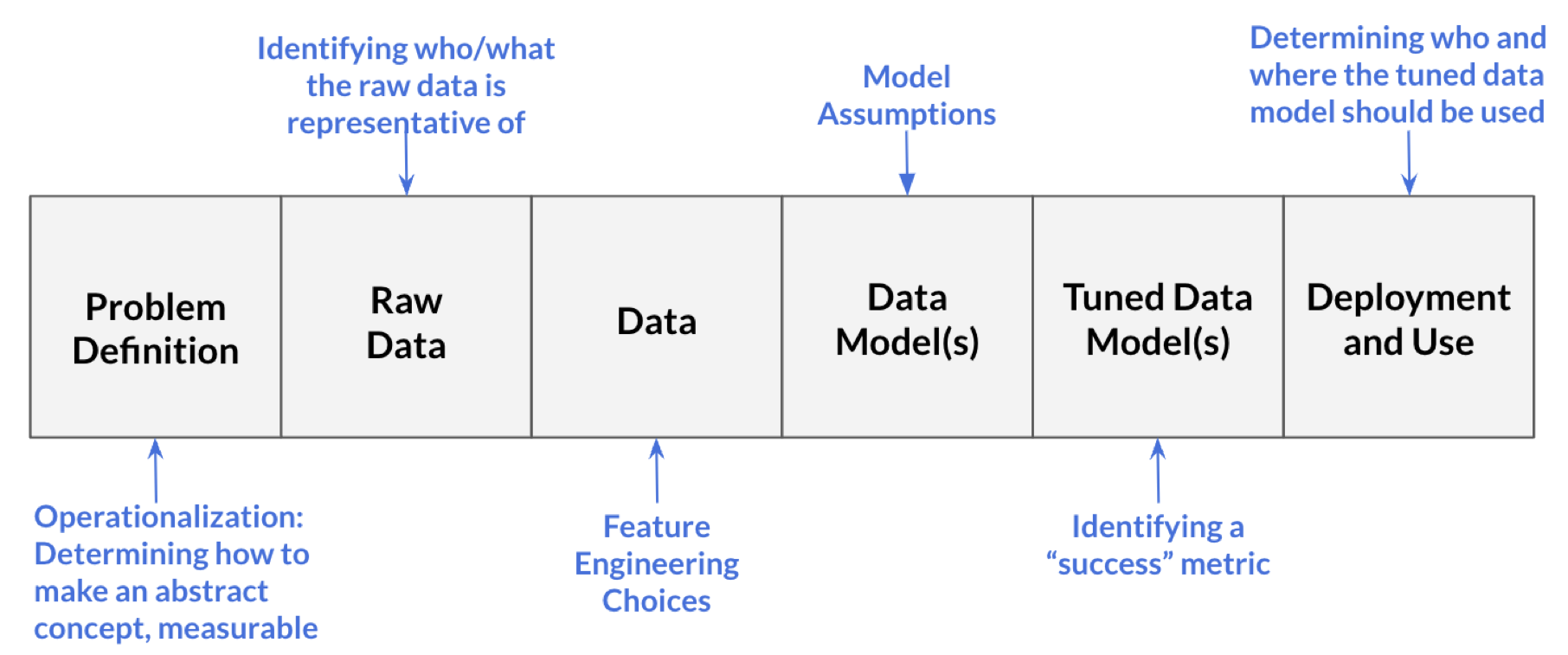
Processes in data science

- Problem definition: Question we wish to answer with data
- What is the likelihood a customer purchases product S?
- Our model (built on training data) is successful if it achieves at least 75% accuracy on testing data
Processes in data science
- Raw data: Information collected by interacting with the world
- Information from each time the customer clicks on an advertisement for product S
- Includes timestamps for each advertisement interaction and the customer’s demographic information
Processes in data science
- Data: Processed form of raw data
- Data table where each row represents a unique customer and the columns are the variables that describe that customer
- Includes information from raw data and engineered variables (e.g., average time between clicks)
- We decide what to do with missing data
Processes in data science
- Data model(s): Product from running input data through learning algorithm (generalize the relationship between variables in the data)
- We choose a logistic regression model of the form
\[ \log(\frac{\pi}{1-\pi}) = \beta_0 + \beta_1 ~ \text{age} + \beta_2 ~ \text{number clicks} + \beta_3 ~ \text{avg time between clicks} \]
Processes in data science
- Tuned data model(s): Data model in which the parameters are adjusted
- Use 5-fold cross validation to determine which variables to include in order to improve model’s accuracy
Processes in data science
- Deployment and usage: Generating predictions (or other output) from the tuned model
- Determine that the model should only be used for customers under a certain age
- Determine only data scientists at the company selling product S should be able to access model and sell products from it
Your data science process
Source: https://scolando.github.io/data-science-ethics/Intro-DS-ethics.html
What are some decisions you have made (or will make) in your project or other data analysis work?